BTE is a python module for automated extraction of body text from web pages. By body-text I mean extract the main textual content from the page and throw away all the extra non-important stuff like sidebars, navigation bars, header, footer, etc. It can also be used to generate short teasers/summaries.
I wrote BTE about 7 years ago and I don’t use it or support it anymore. It worked pretty well when I wrote it originally but I’m not sure how well it works on todays web pages, which may have different tag distributions (e.g. less tables, more javascript).
However, Bill Bushey and Brian Young were using it while doing intern work at Berkman Center at Harvard and they sent me some updates to the code. They managed to get the main algorithm from O(n3) to O(n2). Their changes are in the git repository.
How does BTE work?
BTE extracts the main body of text from a web page. It does this by tokenising the document and performing some shallow processing. The html document is tokenised and represented as a binary string where a 0 represents a tag token and a 1 represents a text token. If we graph cumulative total tokens on the x axis and cumulative tag tokens on the y axis we get a graph something like that shown below.
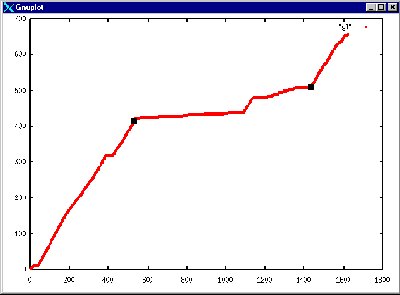
BTE basically works by finding an i and j where we maximise the number of text tokens between i and j and maximise the number of tag tokens below i and above j.
Usage
Install it by copying the file to a directory in your PYTHONPATH.
import sys,BodyTextExtractor
html = open(sys.argv[1]).read()
p = BodyTextExtractor.HtmlBodyTextExtractor()
p.feed(html)
p.close()
x = p.body_text()
s = p.summary()
t = p.full_text()
print "\n\nSummary:\n",s
print "\nBodytext:\n",x
print "\nFulltext:\n",t